Teaching an Open-Source LLM to Write The Office
Fine-tuning a reasoning-first LLM to generate sitcom screenplays with on-brand humor, character voice, and multi-step setups.
Why This Project?
Most LLM demos focus on generic chat or coding. This project demonstrates something different:
Specific Domain
A single sitcom (The Office) with strong, recognizable character voices.
Reasoning-Heavy Format
Each sample includes both a planning / reasoning trace and the final screenplay.
Production Pipeline
Data curation, SFT, RFT, automated evaluation, and visualization.
This case study doubles as:
- A product demo: "What if you could auto-generate new The Office episodes?"
- A skills demo: End-to-end fine-tuning of open-source LLMs for a narrow, stylistic generation task.
System Overview
Goal: Given a high-level sitcom situation (e.g., "Michael uses Pam's post-its to avoid work calls"), generate:
- A reasoning trace that plans beats, character goals, and comedic engines.
- A full screenplay scene consistent with The Office tone.
Reasoning Trace Structure
Each training sample includes a comprehensive creative blueprint. The reasoning trace contains:
1. Storyline Goal
Narrative purpose, core conflict, and comedic goal.
2. Character Objectives
Each character's immediate want or need.
3. Character Dynamics
Interpersonal conflicts and alliances.
4. Meta Reasoning
Writer's room approach — why this is funny.
5. Primary Comedy Engine
Cringe, Dramatic Irony, Absurdity, Escalation.
6. Beat Sheet
Inciting Incident → Rising Action → Climax → Resolution.
7. Talking Head Strategies
How characters use confessionals for comedy.
8. Comedy Tropes Applied
Specific comedic devices used.
Models Compared
Base Model
Gemma-3 1B — Original LLM (no domain fine-tuning)
SFT
CoT Reasoning — Supervised fine-tune on reasoning + screenplay
RFT
Model Grader — Reinforcement fine-tune using LLM-as-judge rewards
LLM-as-Judge Evaluation Criteria
The judge evaluates each screenplay using eight weighted metrics that capture both technical quality and stylistic authenticity:
The highest weights on Character Consistency and Humor Quality — the two elements that define The Office's unique voice.
Training & Results
Reinforcement Fine-Tuning Rewards: How quickly does the policy learn to please the sitcom-style judge?
- Early steps show high variance and lower average rewards.
- The rolling average climbs steadily as the policy learns, then plateaus at a stable style the judge prefers.
- Occasional dips reflect exploration and noisy judge scores, but the overall trajectory trends upward.
RFT Reward Progression
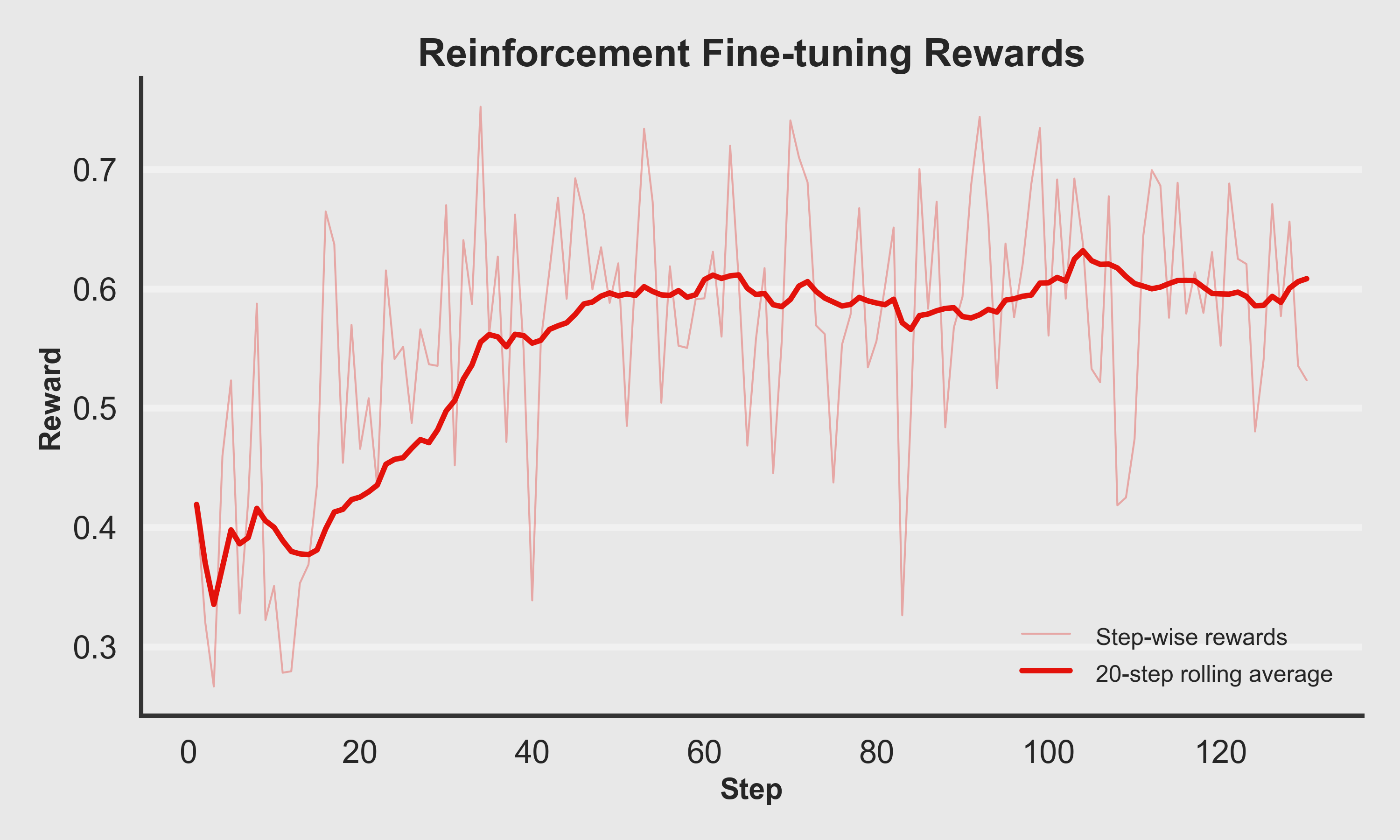
Step-wise rewards (light) and 20-step rolling average (bold). The model gradually learns: don't just be coherent — be character-consistent, witty, and structurally Office-like.
Quantitative Evaluation
All three models evaluated on a held-out set of sitcom prompts, scoring each output with a domain-tuned LLM-as-judge (0–1 scale, normalized).
Score Distribution by Model
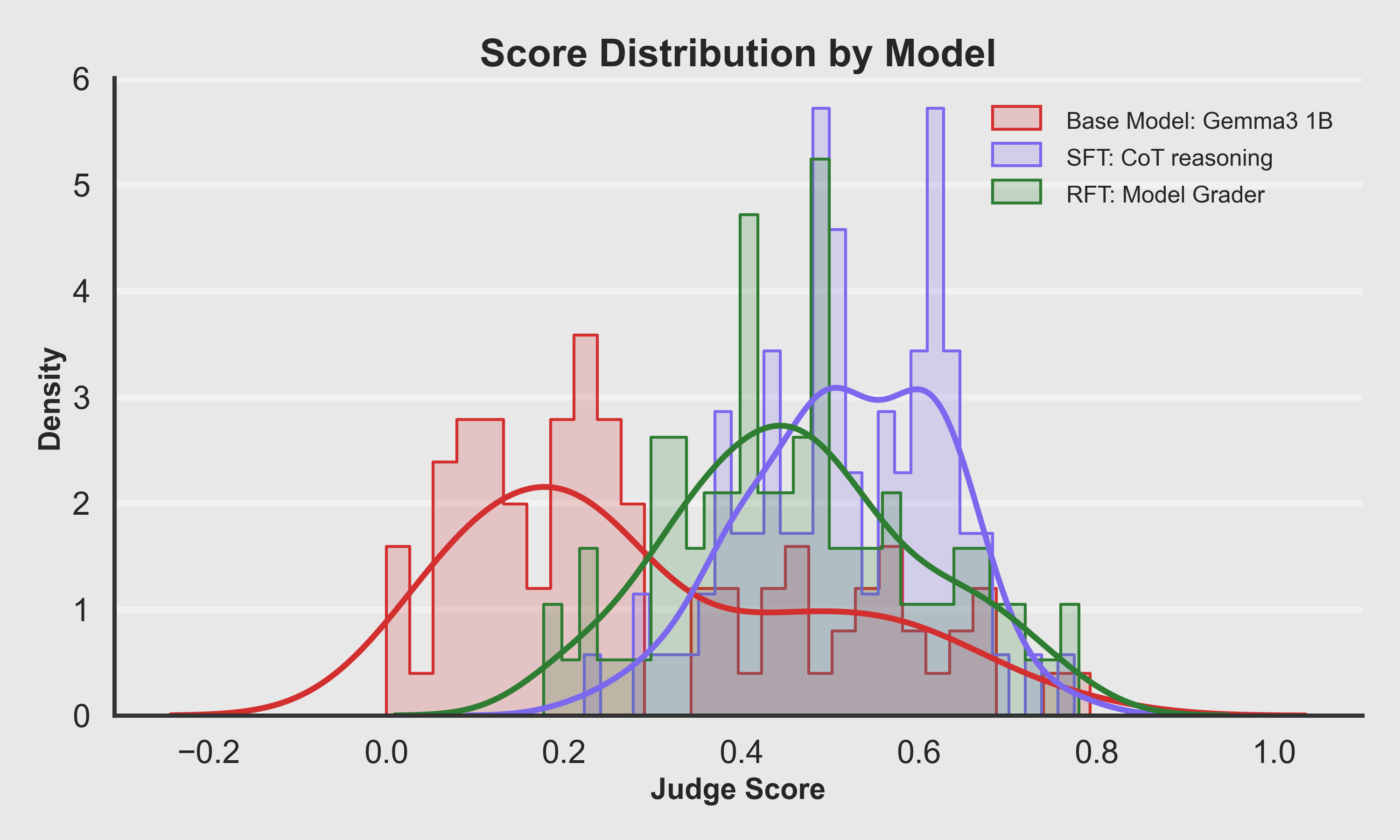
The "cloud" of scores moves to the right as training progresses from Base → SFT → RFT.
Boxplot Comparison
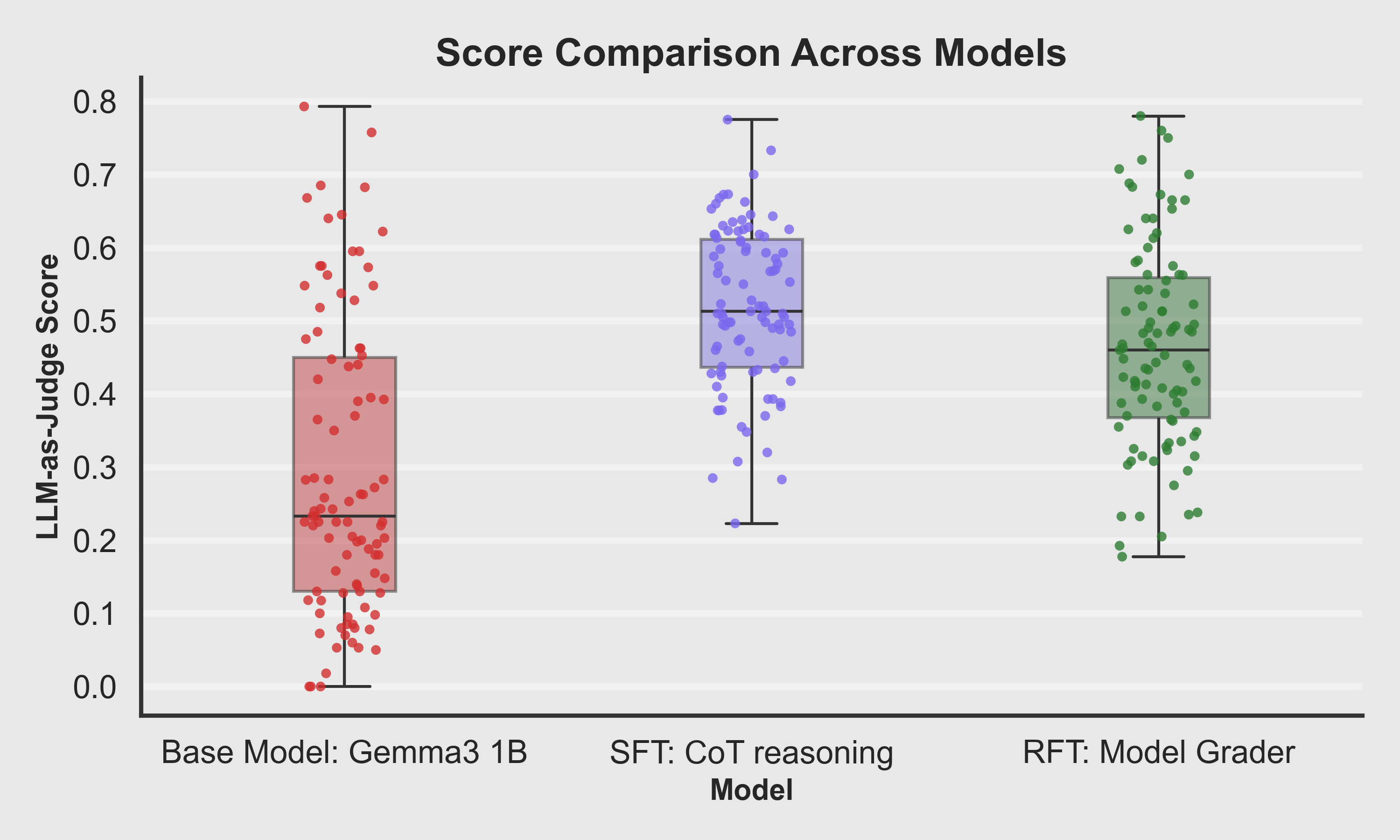
Median score jumps significantly from Base → SFT. RFT retains a higher median with fewer catastrophic failures.
Key Takeaway: Fine-tuning doesn't just help a few cherry-picked cases — it shifts the overall quality level up.
Hero Examples
Compare the output of the Base model, SFT model, and final RFT model. Scores are on the 0–1 normalized LLM-as-judge scale.
Detailed Training Specifications
Training Pipeline Overview
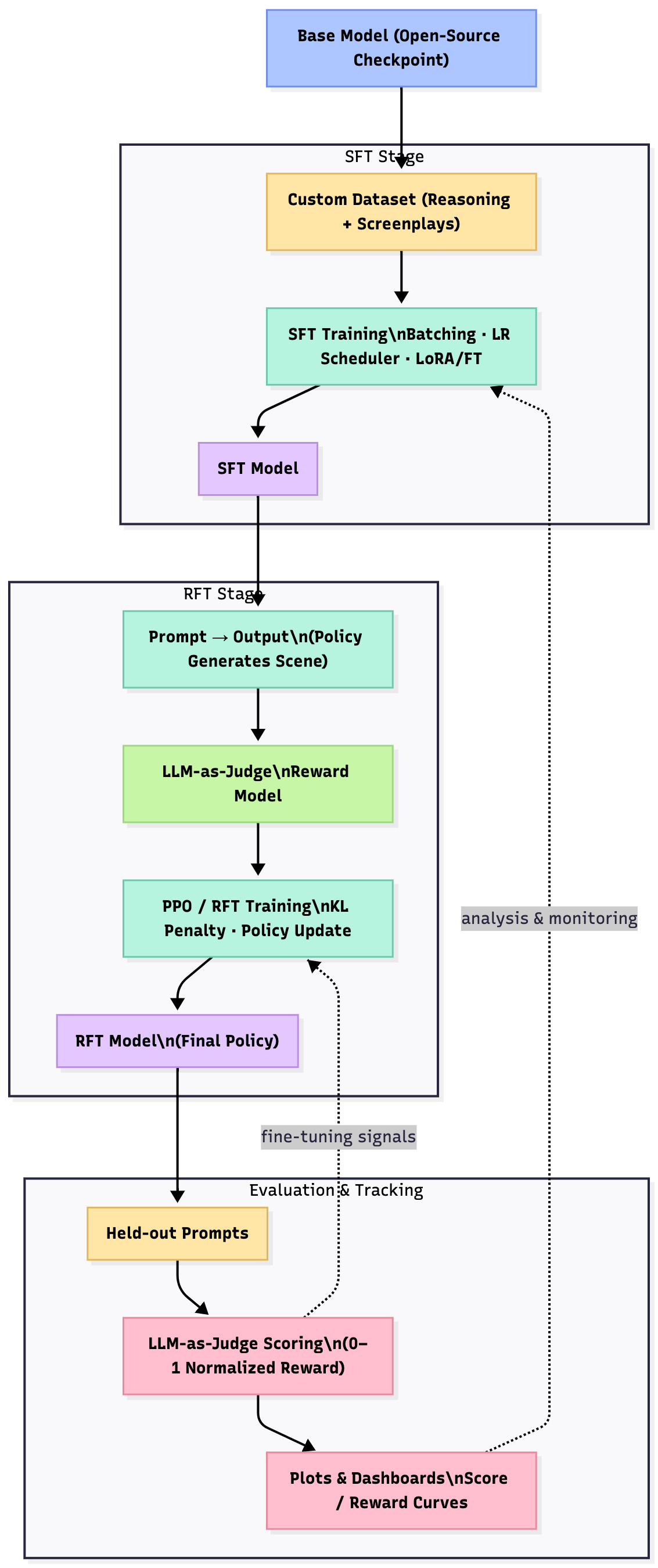
Base model → SFT (reasoning + screenplay) → RFT with PPO using LLM-as-judge rewards.
Data Preparation
SFT (Supervised Fine-Tuning)
RFT (Reinforcement Fine-Tuning with PPO)
Key Learnings
-
1
Problem Framing
Turn a fuzzy idea ("Office-style scenes") into a concrete objective with measurable rewards.
-
2
Custom Data Design
Design a reasoning + screenplay schema. Build prompts and reference scripts to teach the model structure and style.
-
3
Supervised & Reinforcement Fine-Tuning
Run SFT to anchor the model in domain behavior. Layer RFT on top to align with a style-aware judge.
-
4
Evaluation & Visualization
Implement LLM-as-judge scoring. Visualize distributions (boxplots, histograms) and training reward curves. Curate hero examples that connect metrics to human-perceived quality.
-
5
Storytelling & Product Thinking
Package the work as a case study that looks like a product launch: clear problem definition, before/after comparisons, visuals that non-experts can understand.
From Demo to Product: Agentic ScriptWriter Assistant
This trained model demonstrates the foundation for a real-world AI-powered screenwriting co-pilot — a tool for aspiring writers, professional screenwriters, and showrunners to accelerate their creative process while maintaining artistic control.
Instead of replacing writers, the system acts as an intelligent collaborator that handles the mechanical aspects of screenplay formatting while the human focuses on story and vision.
Core Product Architecture
-
1
Story Architect Agent — Brainstorming & Structure Planning
Takes rough situation ideas and character preferences, outputs beat-by-beat scene structure, character dynamics map, and multiple story variations.
-
2
Screenplay Generator Agent — Dialogue & Scene Execution
This is where our trained RFT model powers the system. Takes the structured reasoning trace and generates production-ready screenplay with authentic character voices, mockumentary format, and character-consistent humor.
-
3
Continuity & Quality Guardian Agent — Script Review
Monitors the entire script across multiple scenes, ensuring character arcs, running gags, and show mythology remain consistent. Flags drift and suggests revisions.
-
4
Dialogue Polish & Alternative Generator — Iterative Refinement
Provides A/B/C line variations, punch-up suggestions, and timing/pacing adjustments while preserving the writer's intent.
Business Model: Subscription tiers — aspiring writers get basic agents. Professional showrunners pay for multi-episode management, team collaboration, and custom model fine-tuning on their show's existing episodes. Studios license enterprise versions with proprietary IP training.