Building a Kannada Physics Tutor LLM with Feynman-Style Explanations
Multi-stage fine-tuning pipeline to create a reasoning-first physics tutor in Kannada, combining domain-specific SFT and RAG for intuitive, grounded explanations.
Why This Project?
Most LLMs struggle with conceptual physics explanations in regional languages. This project demonstrates three things at once:
Low-Resource Language
Teaching a model to think in Kannada, not just translate from English.
Feynman-Style Teaching
Intuitive, step-by-step reasoning with analogies — focusing on why, not just formulas.
Multi-Stage Pipeline
Language fluency → Domain reasoning → Factual grounding with RAG.
This case study demonstrates:
- End-to-end fine-tuning for low-resource languages + specialized domains
- How multi-stage SFT compounds improvements (language → domain → grounding)
- Complete evaluation pipeline: LLM-as-judge, quantitative metrics, qualitative analysis
System Overview
Goal: Given a physics question in Kannada (e.g., "How do we derive Laplace's equation for a membrane?"), generate:
- A step-by-step reasoning trace that builds intuition.
- A Feynman-style explanation in natural, fluent Kannada.
- Grounded answers using retrieved physics context (RAG).
Four-Model Progression
The training pipeline uses a staged approach where each model builds on the previous one:
1. Base Model
Gemma 3 1B — General-purpose LLM baseline (no specialization)
2. Kannada SFT
Language Foundation — Fine-tuned on general Kannada text for fluency
3. Physics SFT
Domain Reasoning — Physics concepts + Feynman-style explanations in Kannada
4. Physics + RAG
Factual Grounding — Retrieval-augmented generation with physics knowledge base
Why Multi-Stage Fine-Tuning?
Stage 1 (Kannada SFT): Teaches linguistic fluency independent of domain.
Stage 2 (Physics SFT): Builds conceptual reasoning and Feynman-style intuition on top of that fluency.
Stage 3 (RAG): Adds factual precision by retrieving relevant physics context before answering.
LLM-as-Judge Evaluation
Each model's output is evaluated using an LLM-as-judge with a structured grading prompt. Scores are on a 0–5 scale across four dimensions:
Physics Correctness
Conceptual accuracy and mathematical precision
Reasoning Quality
Step-by-step clarity and logical flow
Kannada Fluency
Natural language quality and proper grammar
Contextual Relevance
Answers the specific question with appropriate detail
Quantitative Evaluation
All four models were evaluated on a held-out set of physics questions, scoring each output with an LLM-as-judge (0–5 scale).
Score Distribution by Model
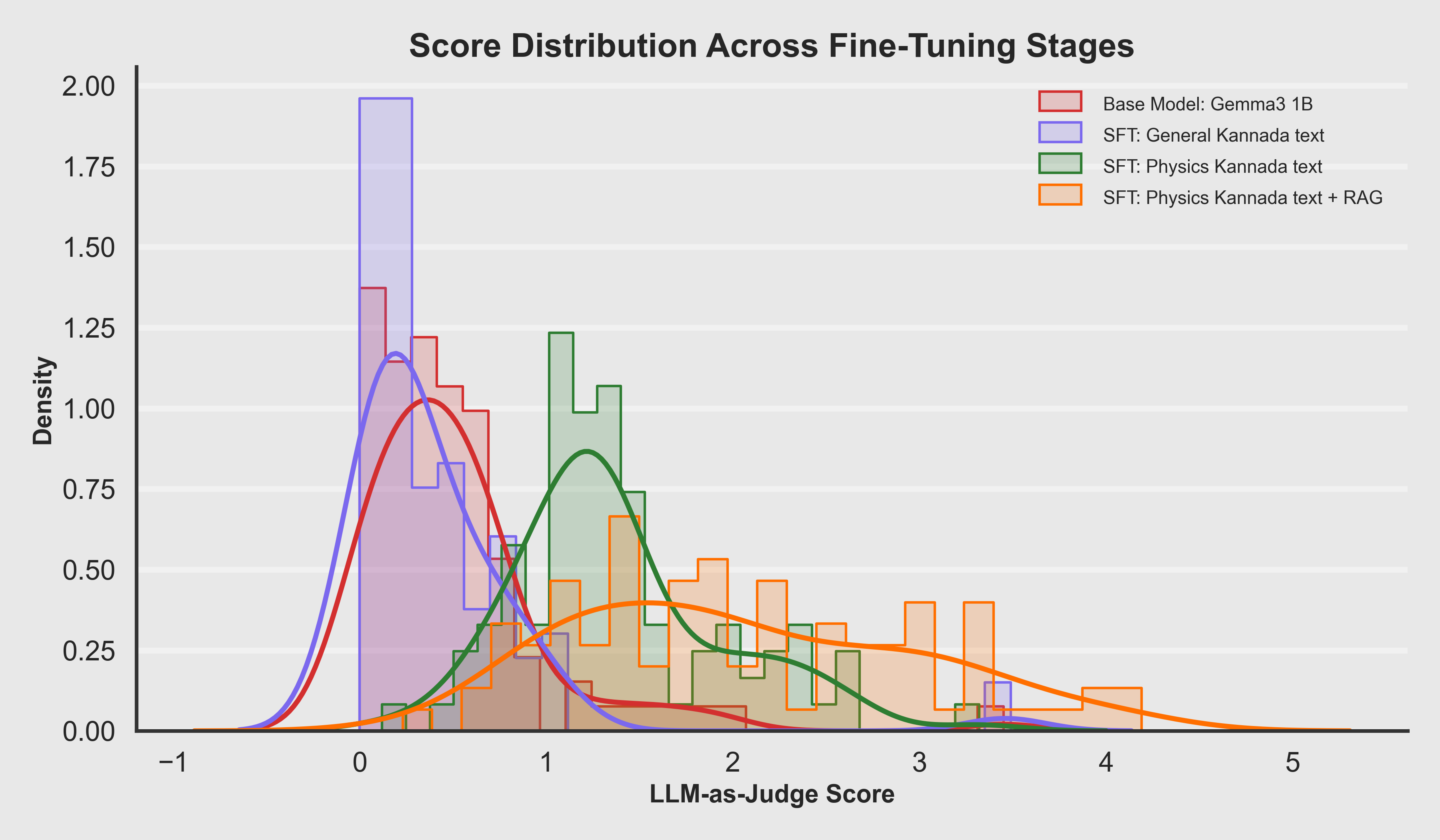
Progressive right-shift in score distributions demonstrates that each stage adds measurable value: fluency → reasoning → grounding.
Boxplot Comparison
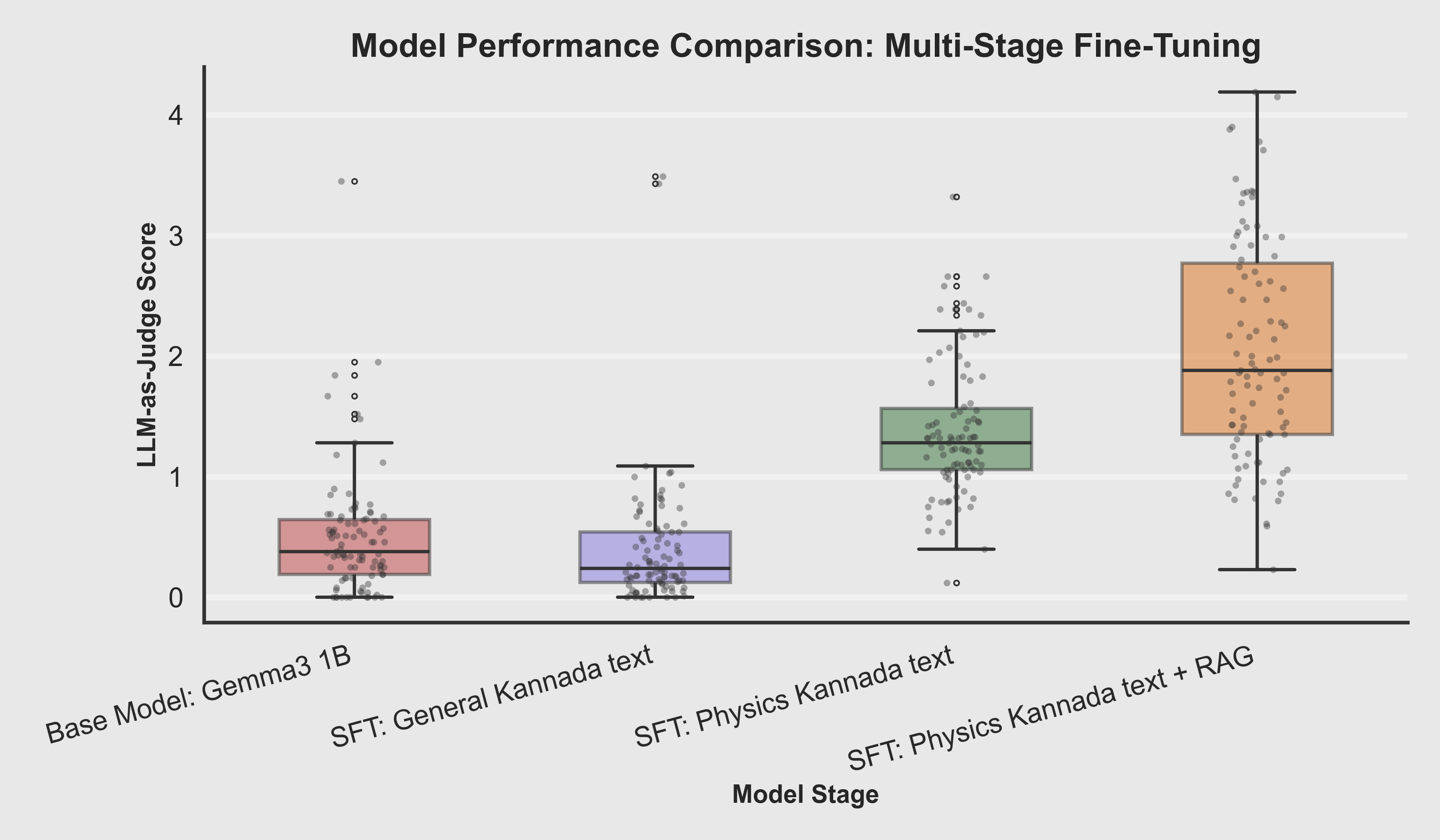
Median score increases dramatically: Base (≈0) → Kannada SFT (0.5) → Physics SFT (2.3) → RAG (3.7). The IQR narrows for final models, showing more consistent performance.
Key Takeaway: Multi-stage fine-tuning doesn't just improve average performance — it systematically reduces failure modes and increases reliability.
Hero Examples
Compare the output quality of all four models on held-out physics questions. Scores are on the 0–5 LLM-as-judge scale.
Detailed Training Specifications
Training Pipeline Overview
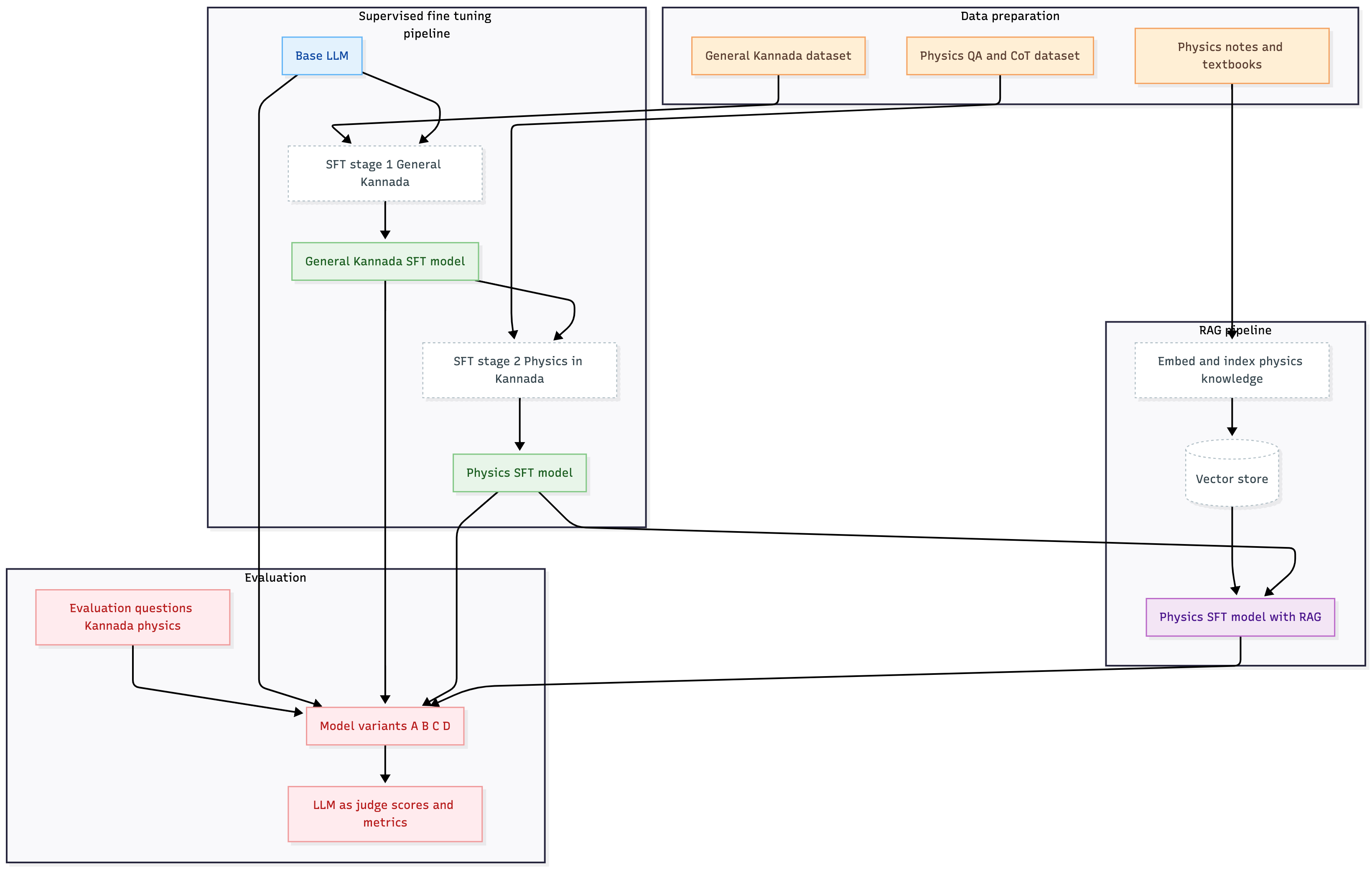
Base model → Kannada SFT → Physics SFT → RAG integration. Each stage compounds improvements from the previous.
Data Preparation
Training Configuration
Hardware: 1× A40 (48 GB VRAM) · PyTorch with HuggingFace Transformers
Stage 1: General Kannada SFT
Stage 2: Physics Kannada SFT
Training Progression:
- Stage 1 reduced eval loss from 4.71 → 2.91 (38% reduction)
- Stage 2 further reduced eval loss from 3.25 → 2.47 (24% reduction)
- Healthy train/eval gap indicates good generalization without overfitting
Key Learnings
-
1
Low-Resource Language Fine-Tuning
Separating language fluency (Kannada SFT) from domain knowledge (Physics SFT) allows the model to learn each skill independently before combining them. This staged approach is more effective than trying to learn both simultaneously.
-
2
Multi-Stage SFT Compounds Benefits
Each stage adds measurable value: language quality → reasoning patterns → factual accuracy. The boxplots clearly show each stage shifts the performance distribution upward.
-
3
RAG as a Grounding Layer
Fine-tuned models can reason well but may still hallucinate details. Adding RAG dramatically improves factual accuracy without additional training.
-
4
LLM-as-Judge for Evaluation
Building a complete evaluation pipeline with LLM-as-judge, quantitative metrics, and qualitative analysis provides a full picture of model capability.
From Demo to Product: AI-Powered Physics Education for Rural India
This trained model demonstrates the foundation for a scalable educational platform designed for government schools and rural communities across India where students lack access to quality STEM education in their native language.
Instead of replacing teachers, the platform acts as an always-available AI tutor that supplements classroom learning and helps students build deep conceptual understanding in their mother tongue.
The Challenge in Rural India
Language Barrier
In rural Karnataka, 85% of students study in Kannada-medium schools, but most quality educational resources are only available in English.
Teacher Shortage
Government schools face chronic shortages of qualified physics teachers, leaving little time for conceptual depth or individual attention.
Rote Learning Culture
Traditional teaching emphasizes memorizing formulas without understanding — exactly what Feynman-style teaching addresses.
Cost of Tutoring
Private physics tutoring costs ₹3,000–5,000/month — unaffordable for families earning ₹15,000/month.
Multi-Agent AI Tutor Architecture
-
1
Concept Explainer Agent — Feynman-Style Intuitive Teaching
This is where our Physics+RAG model powers the system. Generates Feynman-style explanations with analogies, step-by-step reasoning, and visual intuition in Kannada.
-
2
Practice Problem Generator — Adaptive Problem Sets
Generates chapter-aligned practice problems with difficulty progression and detailed worked solutions in Kannada.
-
3
Learning Path Advisor — Personalized Curriculum
Tracks student progress, identifies conceptual gaps, and recommends targeted review topics before advancing.
-
4
Exam Preparation Coach — Board Exam Focused Support
Targeted support for Karnataka SSLC and PUC board exams: previous year question analysis, mock tests, and answer writing practice.
Revenue Model: Freemium — basic concept explanations free for all students. Premium features at ₹99/month ($1.20). Government partnerships and NGO sponsorships subsidize access below poverty line. Same multi-stage fine-tuning approach can be replicated for Hindi, Tamil, Telugu, and other regional languages.